

Bringing it all together 🤖#
In this example we will combine everything we implemented in the previous examples to create one big graph of components. Afterwards we will analyze what we have accomplished. Here is what the code looks like:
import numpy as np
import json
from typing import Optional
from agents.components import MLLM, SpeechToText, TextToSpeech, LLM, Vision, MapEncoding, SemanticRouter
from agents.config import SpeechToTextConfig, TextToSpeechConfig
from agents.clients.roboml import HTTPModelClient, RESPModelClient, HTTPDBClient
from agents.clients.ollama import OllamaClient
from agents.models import Whisper, SpeechT5, Llava, Llama3_1, VisionModel
from agents.vectordbs import ChromaDB
from agents.config import VisionConfig, LLMConfig, MapConfig, SemanticRouterConfig
from agents.ros import Topic, Launcher, FixedInput, MapLayer, Route
### Setup our models and vectordb ###
whisper = Whisper(name="whisper")
whisper_client = HTTPModelClient(whisper)
speecht5 = SpeechT5(name="speecht5")
speecht5_client = HTTPModelClient(speecht5)
object_detection_model = VisionModel(name="dino_4scale",
checkpoint="dino-4scale_r50_8xb2-12e_coco")
detection_client = RESPModelClient(object_detection_model)
llava = Llava(name="llava")
llava_client = OllamaClient(llava)
llama = Llama3_1(name="llama")
llama_client = OllamaClient(llama)
chroma = ChromaDB(name="MainDB")
chroma_client = HTTPDBClient(db=chroma)
### Setup our components ###
# Setup a speech to text component
audio_in = Topic(name="audio0", msg_type="Audio")
query_topic = Topic(name="question", msg_type="String")
speech_to_text = SpeechToText(
inputs=[audio_in],
outputs=[query_topic],
model_client=whisper_client,
trigger=audio_in,
config=SpeechToTextConfig(enable_vad=True), # option to always listen for speech through the microphone
component_name="speech_to_text"
)
# Setup a text to speech component
query_answer = Topic(name="answer", msg_type="String")
t2s_config = TextToSpeechConfig(play_on_device=True)
text_to_speech = TextToSpeech(
inputs=[query_answer],
trigger=query_answer,
model_client=speecht5_client,
config=t2s_config,
component_name="text_to_speech",
)
# Setup a vision component for object detection
image0 = Topic(name="image_raw", msg_type="Image")
detections_topic = Topic(name="detections", msg_type="Detections")
detection_config = VisionConfig(threshold=0.5)
vision = Vision(
inputs=[image0],
outputs=[detections_topic],
trigger=image0,
config=detection_config,
model_client=detection_client,
component_name="object_detection",
)
# Define a generic mllm component for vqa
mllm_query = Topic(name="mllm_query", msg_type="String")
mllm = MLLM(
inputs=[mllm_query, image0, detections_topic],
outputs=[query_answer],
model_client=llava_client,
trigger=mllm_query,
component_name="visual_q_and_a"
)
mllm.set_component_prompt(
template="""Imagine you are a robot.
This image has following items: {{ detections }}.
Answer the following about this image: {{ text0 }}"""
)
# Define a fixed input mllm component that does introspection
introspection_query = FixedInput(
name="introspection_query", msg_type="String",
fixed="What kind of a room is this? Is it an office, a bedroom or a kitchen? Give a one word answer, out of the given choices")
introspection_answer = Topic(name="introspection_answer", msg_type="String")
introspector = MLLM(
inputs=[introspection_query, image0],
outputs=[introspection_answer],
model_client=llava_client,
trigger=15.0,
component_name="introspector",
)
def introspection_validation(output: str) -> Optional[str]:
for option in ["office", "bedroom", "kitchen"]:
if option in output.lower():
return option
introspector.add_publisher_preprocessor(introspection_answer, introspection_validation)
# Define a semantic map using MapEncoding component
layer1 = MapLayer(subscribes_to=detections_topic, temporal_change=True)
layer2 = MapLayer(subscribes_to=introspection_answer, resolution_multiple=3)
position = Topic(name="odom", msg_type="Odometry")
map_topic = Topic(name="map", msg_type="OccupancyGrid")
map_conf = MapConfig(map_name="map")
map = MapEncoding(
layers=[layer1, layer2],
position=position,
map_topic=map_topic,
config=map_conf,
db_client=chroma_client,
trigger=15.0,
component_name="map_encoder"
)
# Define a generic LLM component
llm_query = Topic(name="llm_query", msg_type="String")
llm = LLM(
inputs=[llm_query],
outputs=[query_answer],
model_client=llama_client,
trigger=[llm_query],
component_name="general_q_and_a"
)
# Define a Go-to-X component using LLM
goto_query = Topic(name="goto_query", msg_type="String")
goal_point = Topic(name="goal_point", msg_type="PoseStamped")
goto_config = LLMConfig(
enable_rag=True,
collection_name="map",
distance_func="l2",
n_results=1,
add_metadata=True,
)
goto = LLM(
inputs=[goto_query],
outputs=[goal_point],
model_client=llama_client,
config=goto_config,
db_client=chroma_client,
trigger=goto_query,
component_name="go_to_x",
)
goto.set_component_prompt(
template="""From the given metadata, extract coordinates and provide
the coordinates in the following json format:\n {"position": coordinates}"""
)
# pre-process the output before publishing to a topic of msg_type PoseStamped
def llm_answer_to_goal_point(output: str) -> Optional[np.ndarray]:
# extract the json part of the output string (including brackets)
# one can use sophisticated regex parsing here but we'll keep it simple
json_string = output[output.find("{") : output.rfind("}") + 1]
# load the string as a json and extract position coordinates
# if there is an error, return None, i.e. no output would be published to goal_point
try:
json_dict = json.loads(json_string)
coordinates = np.fromstring(json_dict["position"], sep=',', dtype=np.float64)
print('Coordinates Extracted:', coordinates)
if coordinates.shape[0] < 2 or coordinates.shape[0] > 3:
return
elif coordinates.shape[0] == 2: # sometimes LLMs avoid adding the zeros of z-dimension
coordinates = np.append(coordinates, 0)
return coordinates
except Exception:
return
goto.add_publisher_preprocessor(goal_point, llm_answer_to_goal_point)
# Define a semantic router between a generic LLM component, VQA MLLM component and Go-to-X component
goto_route = Route(routes_to=goto_query,
samples=["Go to the door", "Go to the kitchen",
"Get me a glass", "Fetch a ball", "Go to hallway"])
llm_route = Route(routes_to=llm_query,
samples=["What is the capital of France?", "Is there life on Mars?",
"How many tablespoons in a cup?", "How are you today?", "Whats up?"])
mllm_route = Route(routes_to=mllm_query,
samples=["Are we indoors or outdoors", "What do you see?", "Whats in front of you?",
"Where are we", "Do you see any people?", "How many things are infront of you?",
"Is this room occupied?"])
router_config = SemanticRouterConfig(router_name="go-to-router", distance_func="l2")
# Initialize the router component
router = SemanticRouter(
inputs=[query_topic],
routes=[llm_route, goto_route, mllm_route],
default_route=llm_route,
config=router_config,
db_client=chroma_client,
component_name='router'
)
# Launch the components
launcher = Launcher()
launcher.add_pkg(
components=[
mllm,
llm,
goto,
introspector,
map,
router,
speech_to_text,
text_to_speech,
vision
]
)
launcher.bringup()
Note
Note how we use the same model for general_q_and_a and goto_to_x components. Similarly visual_q_and_a and introspector components share a multimodal LLM model.
In this small code block above, we have setup a fairly sophisticated embodied agent with the following capabilities.
A conversational interface using speech-to-text and text-to-speech models that uses the robots microphone and playback speaker.
The ability to answer contextual queries based on the robots camera, using an MLLM model.
The ability to answer generic queries, using an LLM model.
A semantic map of the robots observations, that acts as a spatio-temporal memory.
The ability to respond to Go-to-X commands utilizing the semantic map.
A single input interface that routes the input to different models based on its content.
We can visualize the complete graph in the following diagram:
Complete embodied agent graph#
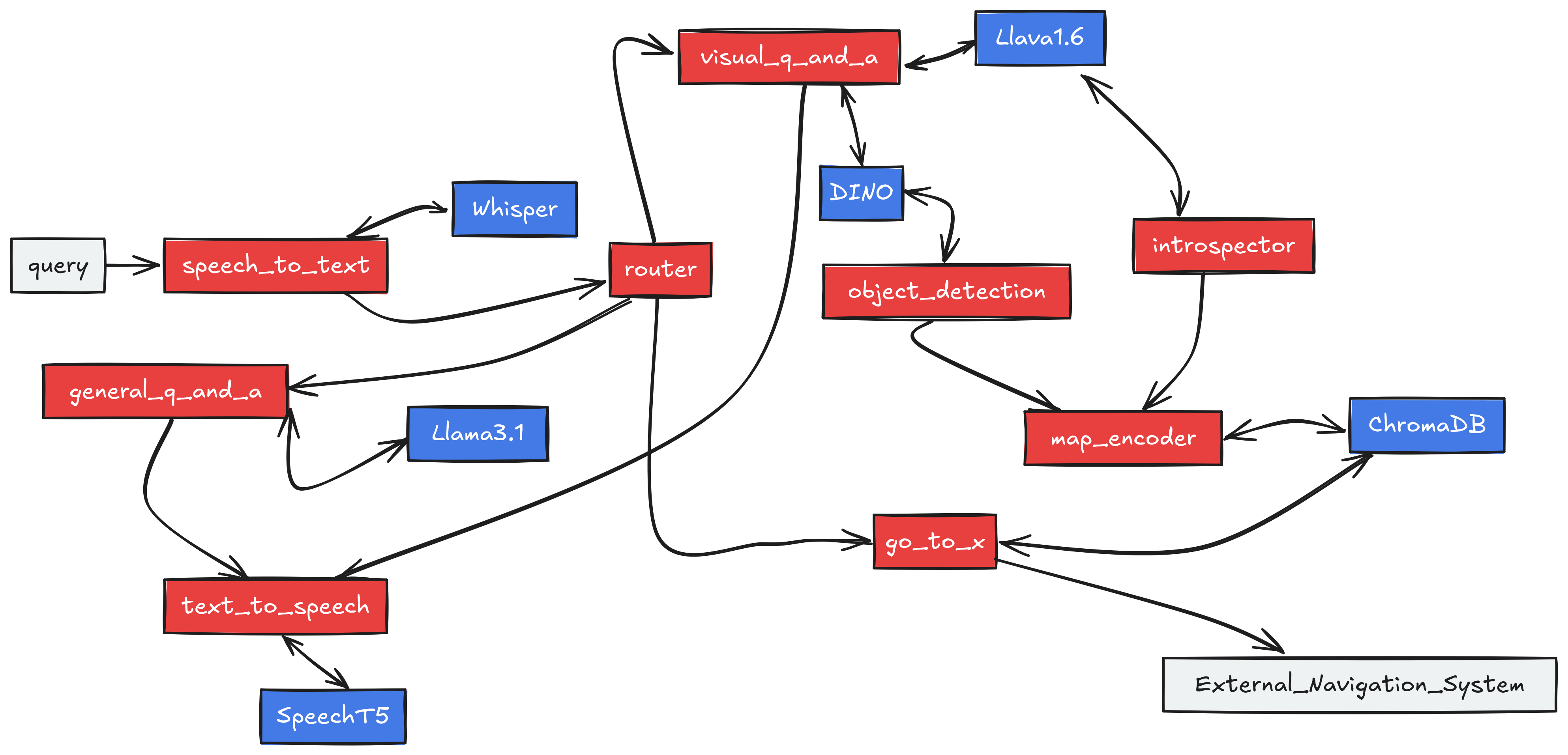
Complete embodied agent graph#